원문
아래 문서를 읽고 정리함
What is a Database Connection?
- Application이 DB 서버와 연결하기 위해선 (당연히) connection이 필요하다. 이 connection을 통해서 application은 SQL 명령을 DB에 보내고 그 결과를 다시 돌려받게 된다.
- 일반적으로 database server와 application server는 분리되어 구성된다. 따라서 DB는 특정 주소와 포트를 열어두고 application이 접근 할수 있도록 한다.(보안설정이 되어있는 경우 credential이 필요하다) 예.MySQL의 default 포트는 3306이다.
- application과 DB의 연결을 위해 TCP-IP가 사용된다.
db_url = jdbc:mysql://HOST/DATABASE
db_driver = com.mysql.jdbc.Driver
db_username = USERNAME
db_password = PASSWORD
- DB에 connection을 맺는 행위는 많은 단계가 필요하기 때문에 high cost 연산이다.
Life Cycle of a Database Connection
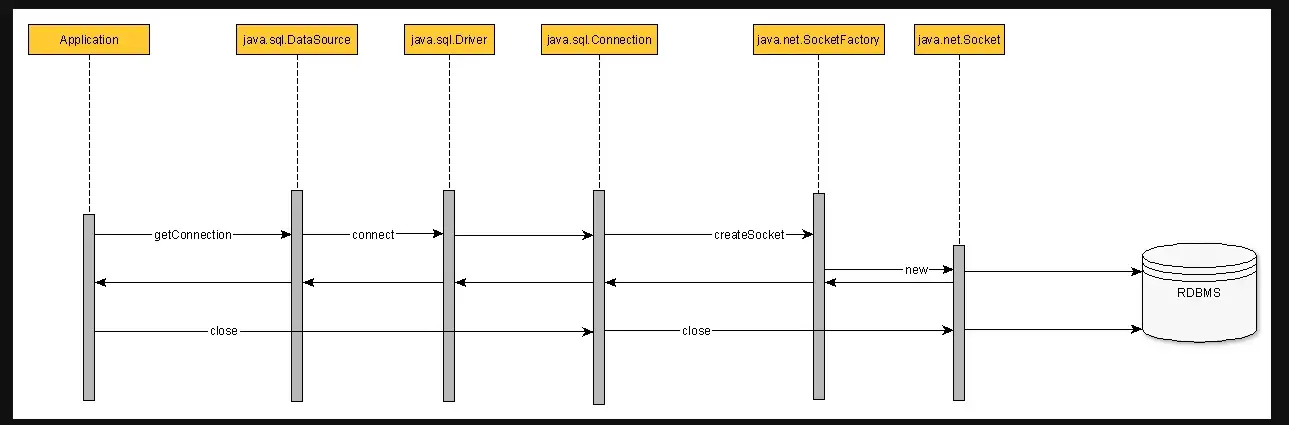
- 위 그림에서 DB와 connection을 맺기까지 많은 과정이 필요하단걸 알 수 있다.
- 사용자가 DB에 요청을 보낼때 마다 connection을 생성하는 작업을 하게 된다면 사용자는 속도의 저하를 겪을 수 밖에 없고, 거기다 요청의 수가 늘어난다면 메모리나, CPU의 사용률이 증가해서 서버가 뻑날수도 있다.
- 이런 이유로 Connection Pool 개념을 도입했다. Connection Pool에 미리 만들어둔 connection을 두고, 요청때마다 꺼내서 재사용하는 방식이다.
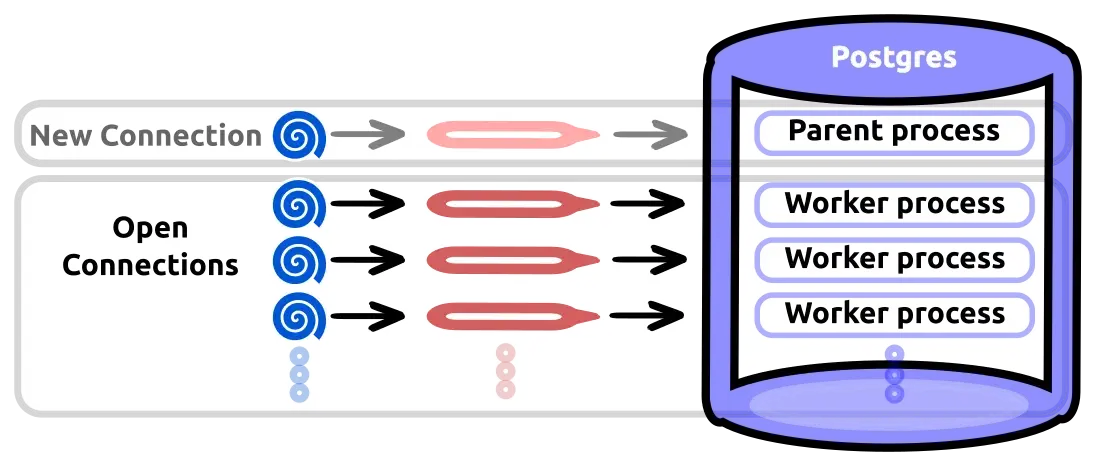
- 위 그림은 Connection pool이 존재하지 않는 경우를 보여준다.
- 매 사용자의 요청마다 connection을 생성한다.
- postgre에선 parent 프로세스가 worker 프로세스를 생성하는데, 이 생성하는 작업도 또다른 오버헤드가 된다. (사용하는 DB에 따라connection 생성뿐만 아니라 서버에 따라 프로세스 생성작업이 추가될수도 있다.)
What is a Database Connection Pool?
- Connection Pool은 connection 생성에서 발생하는 성능적 문제를 해결하는 테크닉이다.
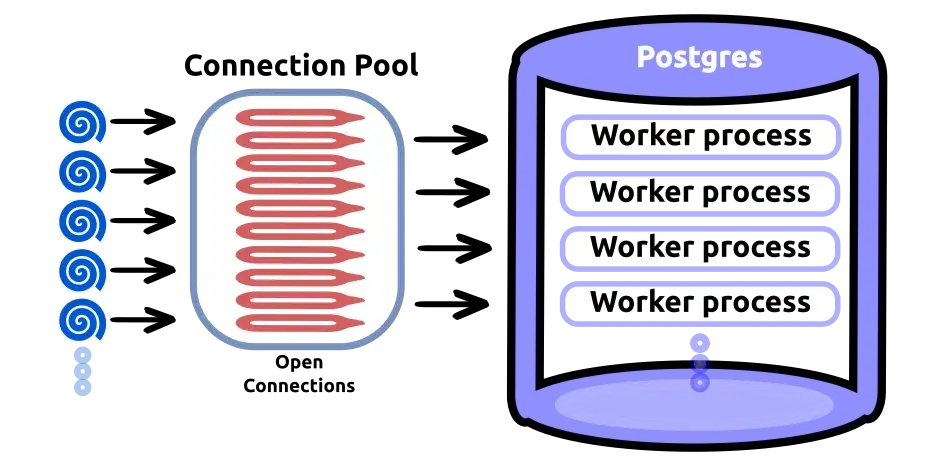
- Connection Pool은 application이 startup에 앞서 생성된다. 그 이후 connection을 DB 접속이 필요한 application간 공유하도록 한다.
- application이 시작될때, provider는 default로 10개 정도의 connection을 만들어서 pool에 준비시켜둔다.
- DB Connection pool은 application server의 메모리를 점유한다.
- connection object는 실제 database connection을 래핑하고 있기 때문에 application 입장에서는 DB의 복잡한 구조를 알 필요 없이 connection object만 다루기만 하면된다.
- connection의 라이프 사이클은 Pool Connection Manager에 의해 관리된다.
- Connection Pool을 통해서 최소한의 connection만 생성한채 수많은 request를 처리하는 서비스를 만들 수 있다.(이런 방식을 Multiplexing이라 한다. 회로 시간에 배운 멀티플렉서 모양을 떠올리면 됨)
- Connection Pool의 컨셉은 Server Thread Pool이나 String Pool과 유사하다.(이 2개 모두 생성 과정에서 발생하는 오버헤드를 줄이기위해 미리 자원을 만들어두고 재사용하는 메커니즘을 가짐)
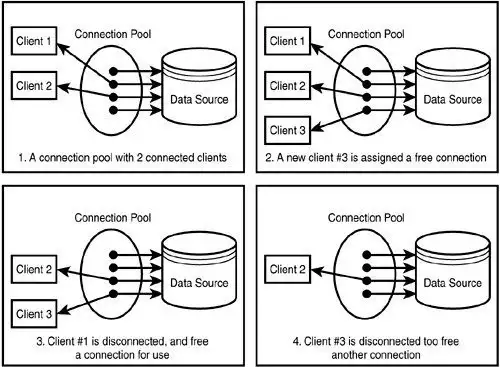
How is a Database Connection reused from the Connection Pool?
Where to place the Database Connection Pool?
- connection pool의 위치는 2가지가 있다
1. Database Connection pool at the Client level
- application이 실행되면 해당 서버의 메모리를 점유해서 connection pool을 만드는 방식이다.
- 가장 기본적으로 사용되는 Connection Pool 생성 위치다.
- 그림에서도 알 수 있듯이 다른 service와 connectioin pool을 공유하지 않는 것이 특징이다.
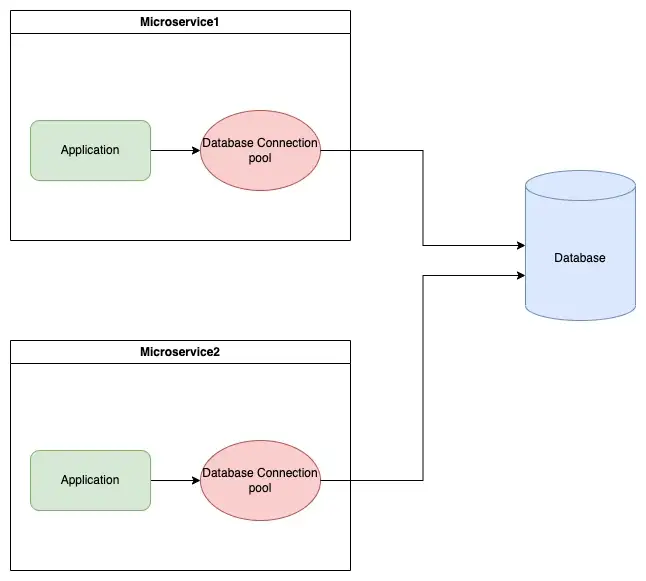
장점
- application이 자신의 메모리에 있는 connection pool을 사용하기 때문에 latency가 낮다.
- connection pool 클라이언트 서버에만 존재하기 때문에 보안 측면에서 다른 방법보다 낫다.
단점
- 각 서버마다 connection pool이 있기 때문에 모니터링이 어렵다.(서버마다 모니터링 해야함)
2. Shared Database Connection pool as a separate middleware
- connection pool을 application과 분리된 특정 서버에서 관리하는 방식이다.
- connection pool의 관리를 중앙화할 수 있다.
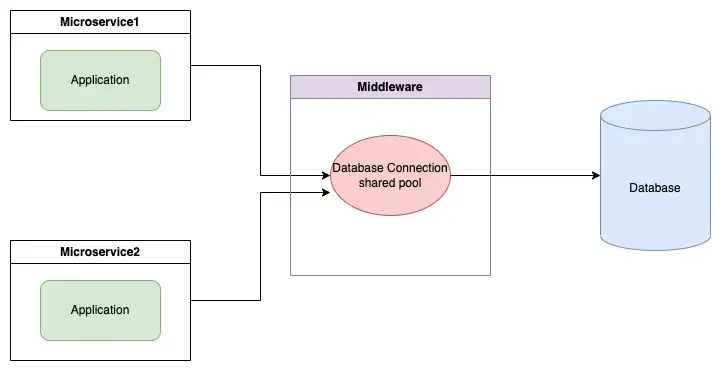
장점
- 유연하다 - 데이터베이스를 변경하기에 용이하다
- 중앙화에 의한 손쉬운 모니터링
단점
- 새로운 레이어가 추가된 것이기 때문에 latency가 증가한다.
- conection pool이 있는 서버가 다운되면 모든 application이 영향을 받는다.
- connection pool이 있는 서버가 보안에 뚫린다면 잠재적으로 모든 application이 위험에 노출된다
Performance Issues With Connection Pools
- 요청이 증가함에 따라서 connection pool에 connection이 부족할 수 있으므로 서비스에 맞는 적절한 pool size를 설정하는게 중요하다.
- connection pool을 너무 크게 설정한 상태에서 요청을 받아내면 DB자체에 부하가 걸릴 수 있다. DB 서버가 처리할 수 있는 connection을 고려해야한다. 잘못하면 DB 자체에 과부하가 걸려서 다운될 수 있음.
- pool size를 산정할때 중요한 요소는 평균적인 Transaction 시간, 요청수 등이 있다.
Connection pool implementations for Java
- 자바 진영에서 많이 사용되는 connection pool 구현체로는 HikariCP, Tomcat JDBC, Apache Commons DBCP2, pgBouncer, c3p0가 있다.